
Fondements des bases de données relationnelles
Objectif pédagogique : Découvrir les concepts essentiels des SGBD relationnels, schémas et clés pour structurer efficacement les données.
À la fin de ce chapitre, tu seras capable de…
- Identifier les caractéristiques des systèmes de gestion de bases de données relationnelles
- Définir la structure d’un schéma de base de données avec les types appropriés
- Distinguer les rôles des clés primaires et étrangères dans les tables
- Analyser l’organisation des données dans les tables relationnelles
💡 Prérequis : Notions de base en informatique et compréhension des concepts de données structurées
Mise en contexte
Vous utilisez quotidiennement des applications qui stockent des millions de données : comptes bancaires, profils sociaux, commandes en ligne. Comment ces informations sont-elles organisées pour être retrouvées instantanément ? Découvrez les fondements des bases de données relationnelles qui structurent notre monde numérique, depuis les tables de véhicules jusqu’aux systèmes complexes d’entreprise.
Introduction
1 – Les système de gestion de base de données relationnelles
On distingue deux grandes familles de SGDB : les SGDB relationnelles (SGDBR) et les SGDB NoSQL.
2 – Les schémas
Regardons un exemple de table : ici cette table appelée Vehicules et contient des données sur différents véhicules.
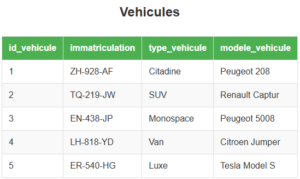
Chaque ligne de la table représente donc un véhicule et les colonnes correspondent aux caractéristiques de ces véhicules. Lorsque nous parlons de schéma, nous pouvons voir ici que cette table a 4 colonnes id_vehicule, immatriculation, type_vehicule et modele_vehicule : la première, consituée de nombres entiers, correspond à l’identifiant du véhicule, la deuxième constituée de chaînes de caractères représente le numéro d’immatriculation du véhicule, la troisième donne le type de véhicule et la dernière fournit la marque et le modèle du véhicule.
Nous venons de définir le schéma de cette table. Nous avons donné le nom et le type de chacune des variables. On peut représenter la table de manière formelle avec la formule suivante :
Vehicules(id_vehicule, immatriculation, type_vehicule, modele_vehicule)
Les types :
Les colonnes d’une table ont un type de données bien défini. Les types de variables peuvent varier d’un SGDB à l’autre mais on retrouve classiquement les types suivants :
- INTEGER
Ce type est utilisé pour stocker des nombres entiers, positifs ou négatifs. Il est couramment employé pour les identifiants, les compteurs ou les valeurs discrètes ne comportant pas de décimales.
- FLOAT
Il permet de représenter des nombres réels avec une précision approximative. Il est adapté aux valeurs nécessitant des décimales.
- NUMERIC (ou DECIMAL)
Il permet de stocker des nombres décimaux avec une précision fixe et définie à l’avance. Contrairement au FLOAT, il garantit une exactitude parfaite des valeurs décimales, ce qui le rend particulièrement adapté aux données financières ou monétaires où chaque centime compte.
- BOOLEAN
Il ne peut prendre que deux valeurs : vrai ou faux (true ou false). Il est parfait pour représenter des états binaires comme la disponibilité d’un produit, l’activation d’une option ou la validation d’une information.
- DATE
Il sert à stocker une date sans information d’heure, généralement sous la forme année-mois-jour. Il est utilisé pour enregistrer des événements calendaires, comme des dates de naissance ou de création.
- DATETIME (ou TIMESTAMP)
Ce type combine une date et une heure, permettant de représenter précisément un instant dans le temps. Ce type est utile pour tracer des événements horodatés, tels que des transactions ou des connexions.
- DOUBLE
Il correspond à un type de nombre réel en double précision. Il offre une plage de valeurs et une précision supérieures à FLOAT, tout en restant une représentation approximative.
- VARCHAR
Il est utilisé pour stocker des chaînes de caractères de longueur variable. La taille maximale est définie à la création de la colonne, ce qui permet d’optimiser l’espace de stockage tout en offrant de la flexibilité pour les données textuelles.
3 – Les clés
3.1 – Les clés primaires :
À contrario, les colonnes immatriculation, type_vehicule et modele_vehicule ne subissent pas ces contraintes : deux véhicules peuvent avoir le même type, la même marque et le même modèle. Le fait que la colonne id_vehicule est la clé primaire, la table Vehicule peut être représentée avec la notation suivante :
Vehicules(id_vehicule, immatriculation, type_vehicule, modele_vehicule).
La clé primaire est soulignée dans la représentation de la table. Une entreprise de location de véhicules dispose d’une base de données pour stocker les informations sur les véhicules, les clients, les reservations et les factures entre autres. La base de données est constituée de plusieurs tables reliées entre elles. Parmis ces tables il y a la table Clients :
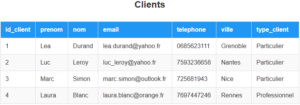
3.2 – Les clés étrangères :
Dans la base de données de l’entreprise, il y a une table nommée ‘Reservations’ qui enregistre chaque réservation des clients :
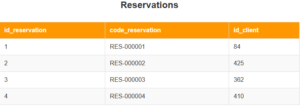
La table Reservatios peut se représenter de la façon suivante : Reservations(id_reservation, code_reservation, id_client)
On remarque que la clé primaire de la table Clients est référencée dans la table Reservations. On dit alors que la colonne id_client dans la table Reservations est une clé étrangère (ou foreign key). La vraie représentaton de la table Reservations est alors :
Reservations(id_reservation, code_reservation, #id_client)
Le caractère # est utilisé par convention pour désigner une clé étrangère.
3.3 – Les clés composites :
4 – Les schémas relationnels
On a vu que les tables pouvaient avoir des relations entre elles via les clés étrangères. La définition de ces relations correspond à la création d’un schéma relationnel. On représente généralement le schéma relationnel par des diagrammes UML (figure ci-dessous). On peut distinguer 3 types de relations selon le nombre d’entités mises en relation :
- One to One : une ligne d’une table est associée à une et une seule ligne d’une autre table.
- One to Many : une ligne d’une table peut être associée à une ou plusieurs lignes d’une autre table.
- Many to Many : plusieurs lignes d’une table peuvent être associées à une même ou à plusieurs lignes d’une autre table.
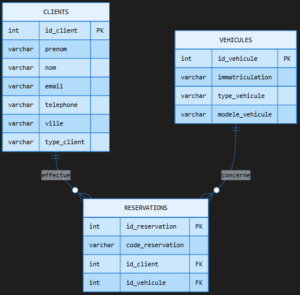
5 – Conclusion
💡 À retenir :
- Les clés primaires identifient de manière unique une ligne d’une table.
- Les clés étrangères sont les clés primaires d’autres tables.
- Les clés peuvent être composites.
- Les différents schémas relationnels.
Nous savons maintenant ce qu’est une base de données relationnelles ainsi que quelques-unes de ses caractéristiques. Nous pouvons à présent suivre le cours sur le langage SQL. Il nous permettra de créer des requêtes pour récupérer des données pertinentes d’une base de données relationnelle.